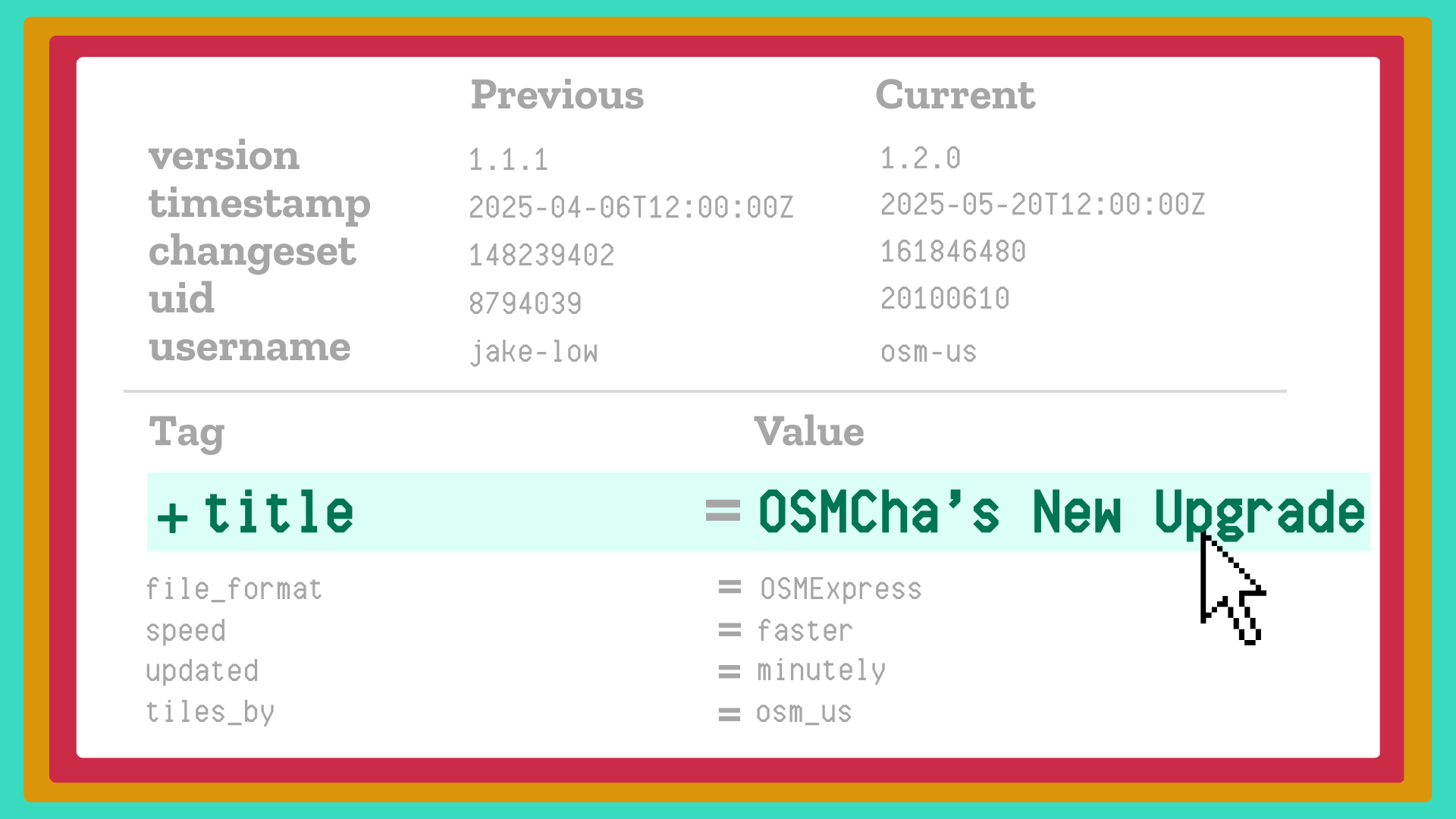
OSMCha, the OpenStreetMap changeset review and validation tool, got quite a bit faster recently. If you’ve used OSMCha over the past year or so, you may have noticed that it often took 15 to 30 seconds to display a changeset, and sometimes would fail to load at all. OSMCha users were telling us that this made reviewing changesets frustrating and difficult, so over the past few months I’ve put a lot of effort (spoiler alert: 200+ hours!) into making OSMCha faster. To do this, I made big changes to how OSMCha works under the hood. If you’d like to learn more about how OSMCha works, the rest of this post is for you.
Background
In OpenStreetMap, a changeset is a group of related map edits, made by a single user and typically in a single editing session. When you click “Save” in iD or “Upload” in JOSM, you’re creating and uploading a changeset. This changeset contains all of the edits you made to individual elements on the map. It also has metadata, like your OSM username, a timestamp, and the description you wrote about your edits. Changesets are stored in the OSM database and record the history of edits to the map over time.
OSMCha is an application for viewing OpenStreetMap changesets. To do this, OSMCha needs data about everything that was modified: specifically, it needs to know the complete old and new versions of all elements that were affected by the change, directly or indirectly.
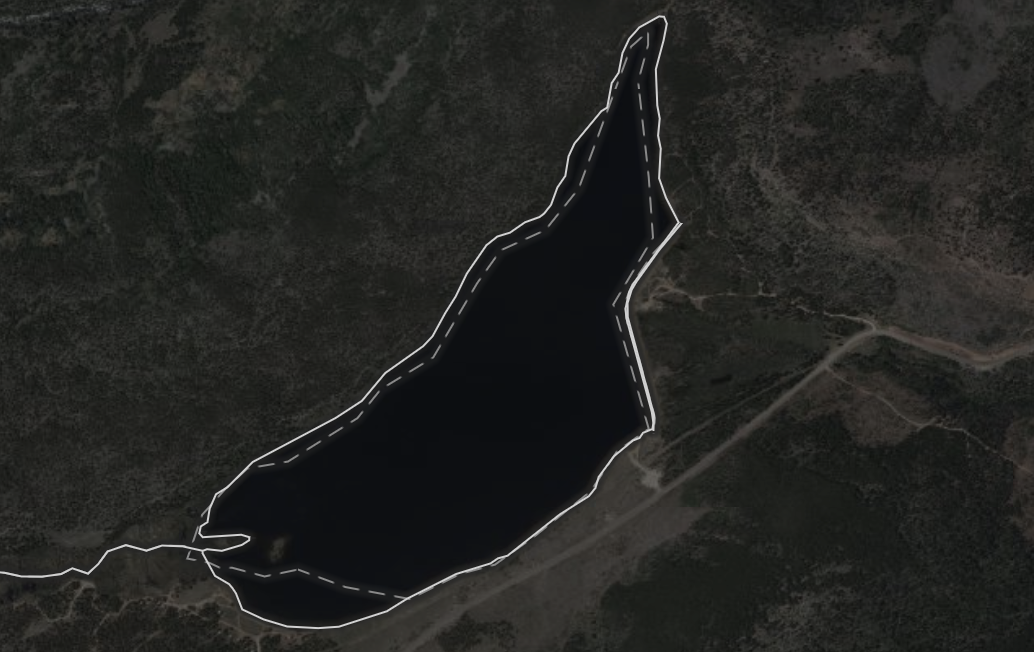
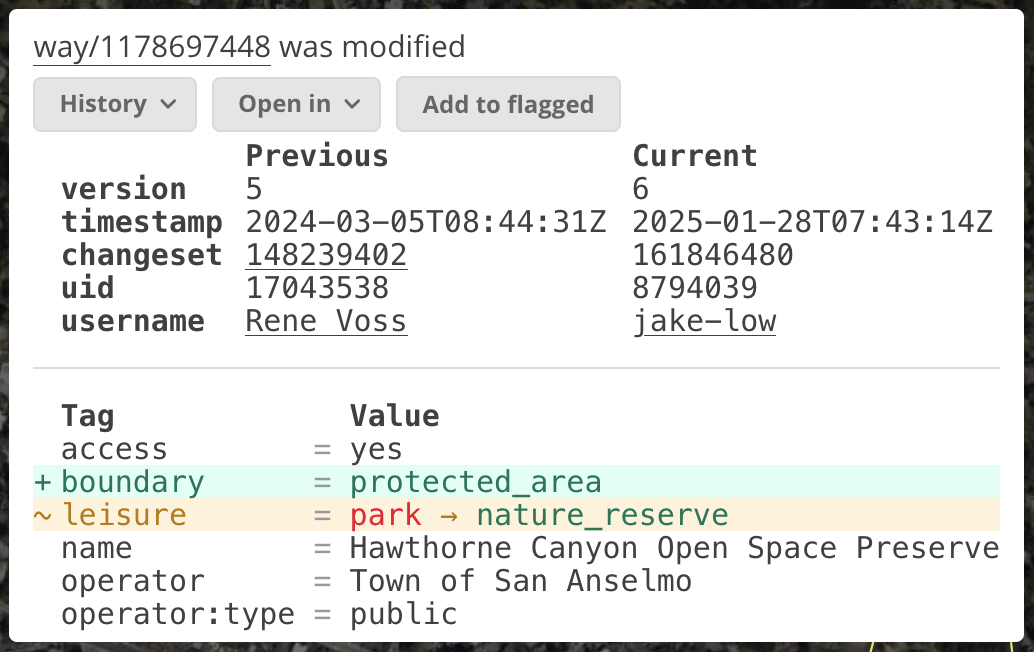
To show changes to the shapes of elements (left) and changes to their tags (right), OSMCha needs to know what both the old and new versions of those objects were for a given changeset.
Changesets from openstreetmap.org don’t contain all of this information “off the shelf”. When you download a changeset from openstreetmap.org via the API (which looks like this), it only contains the new versions of elements, not the old versions. It also does not contain elements that were modified indirectly (e.g. moving some nodes that are part of a way changes the way’s shape, but does not actually generate a new version of that way, so only the nodes would be included in the changeset). These changeset files are optimized to be small in size and easy to compute (they directly match OSM’s underlying data model), but because of this they don’t contain enough detail for visually presenting the scope of the changes to a human. The changes in the planet.openstreetmap.org replication files have this same limitation.
To get the data required to visualize changesets, OSMCha needs to process changesets from the OpenStreetMap API and “augment” them with additional context. These “augmented diffs” are computed in advance and then fetched by the osmcha.org website when you view a changeset.
How OSMCha used to work
Until recently, OSMCha relied on Overpass to generate these augmented diffs. Overpass is a queryable database system for OSM (and the same technology that powers overpass-turbo.eu). For each new changeset, OSMCha would run an Overpass query to find the old and new versions of each element, and store the results in an S3 bucket called real-changesets. The osmcha.org website would then fetch data from this bucket whenever you viewed a changeset.
Sidenote: In principle the real-changesets data was free for anyone to use, but it was stored in a bespoke JSON-based format designed specifically for OSMCha, and so in practice OSMCha was the only software that ended up using this data.
There were some problems with this approach. Overpass is an impressive and flexible tool, but it’s not meant for this kind of workload, so building augmented diffs in this way is expensive and fairly slow. The Overpass query we use is also prone to false positive matches if two changesets occur in the same area in a very short time window, which means OSMCha occasionally shows changes that aren’t actually part of the changeset you’re looking at.
But the biggest problem turned out to be that this process would frequently fail. This could happen when processing very large changesets, which would cause our Overpass server to run out of memory, or if our Overpass server happened to be under heavy load. It could even happen if there was a network blip between the Overpass server and the machine building the diffs (these two servers were on different continents).
When processing of a changeset failed, it meant there would be no data for that changeset in the real-changesets bucket. If you try to load that changeset on osmcha.org, the website will detect that the data is missing and fall back to running the same Overpass query to try and compute the data it needs. This is what was happening any time you tried to view a changeset on OSMCha and it took 30+ seconds to load: you were waiting for an ad-hoc Overpass query to complete, since the changeset wasn’t found in the real-changesets bucket. Ironically, this was happening regularly enough that it created a vicious cycle: users on the website would encounter missing changesets, which would trigger requests to our Overpass server, creating additional load and making the real-changesets pipeline more likely to fail again.
How OSMCha works now
Last month, I finished and deployed a major change to the way OSMCha works. Instead of using the real-changesets data, osmcha.org now loads augmented diffs from a new service called adiffs.osmcha.org. These augmented diffs are in a standard format called Augmented Diff XML, which is supported by various other software in the OpenStreetMap ecosystem.
OSMCha no longer uses Overpass to build these diffs. Here’s how it works instead:
-
A server stores a full mirror of the OpenStreetMap database in OSMExpress format. OSMExpress is a database file format designed specifically for OpenStreetMap data. It makes it possible to efficiently update data in place, allowing you to keep a local copy of OSM in sync with the main database.
-
Every minute, we download a replication file from planet.openstreetmap.org, which contains all of the edits that were made to OSM during the previous one-minute window. The replication file only contains new versions of modified elements, and does not contain elements that were modified indirectly, so we need to augment it. We also need to split it up into a separate diff for each changeset.
-
The OSMExpress database contains the old versions of all of these modified elements, so we can construct an augmented diff by pairing up the old version of each element (from the OSMExpress database) with the new version (from the replication file). We can also use the OSMExpress database to find elements that were indirectly affected (like ways whose nodes were modified) and include those in the augmented diff.
-
Once these diffs are built, we upload them to the adiffs.osmcha.org server so that they are available for the osmcha.org website to load and use.
-
Finally, we use the replication file to update the OSMExpress database, overwriting the old versions of modified elements with new versions, inserting elements that were created, and removing elements that were deleted. This brings our local data in sync with the openstreetmap.org database, so that we’re ready to process the next replication file in a minute.
This new process for building augmented diffs is about 10 to 100 times faster than using an Overpass query. It also uses less memory; so far, we haven’t seen any examples of the process failing because it ran out of RAM while processing a changeset. Since it uses less CPU and RAM, we can comfortably run the new process on less expensive hardware. And since it’s less prone to failure than the old system, it means that a pre-computed augmented diff is nearly always available for the osmcha.org website to load, so OSMCha can show you any changeset you want almost instantly.
The augmented diffs on adiffs.osmcha.org are available for anyone to use. Please reach out to us if you’re interested in building software that makes use of this service.
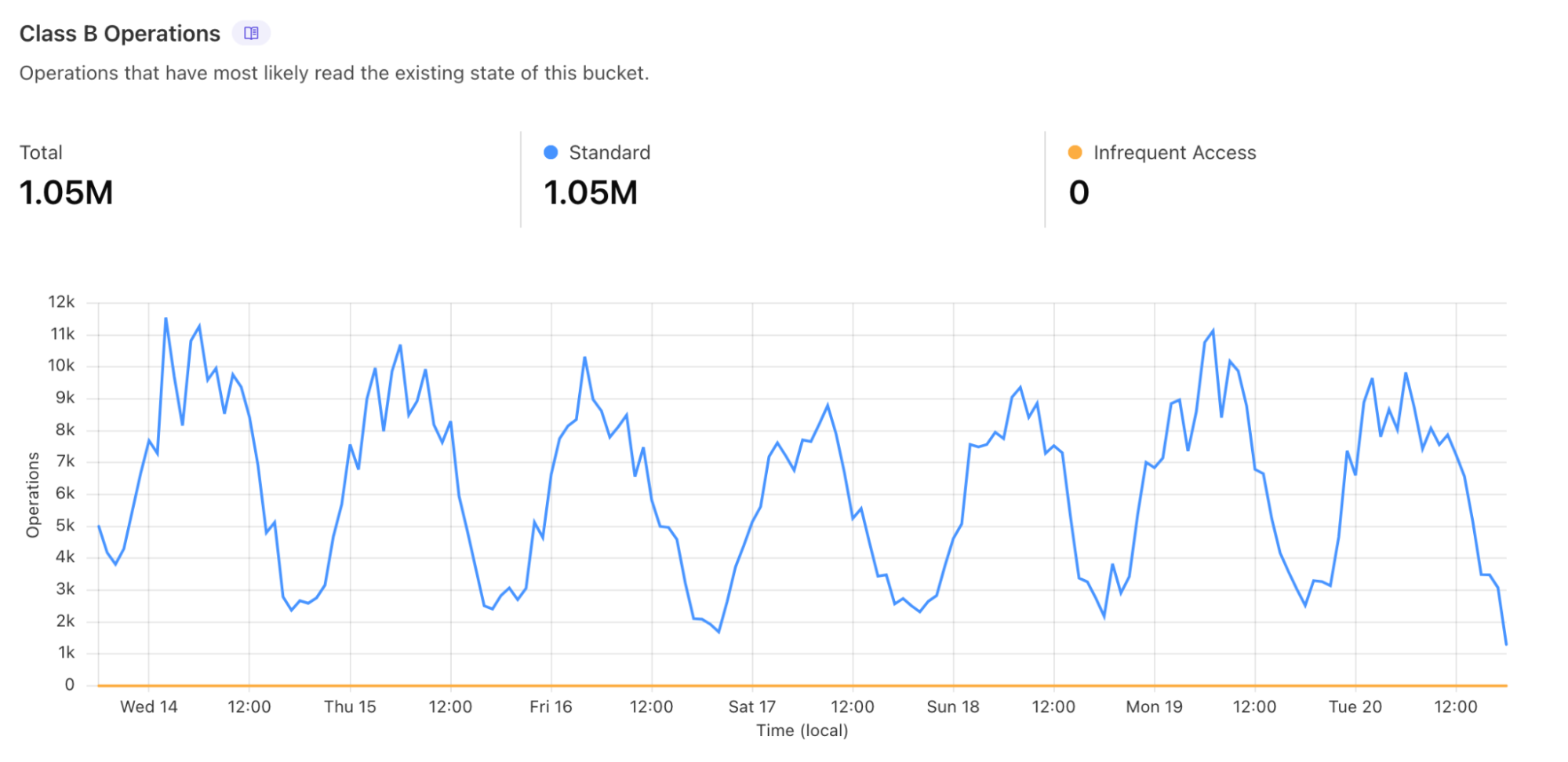
Graph showing augmented diff requests on adiffs.osmcha.org over the last 7 days.
What else changed
Although osmcha.org looks mostly the same after the change, a lot of work went on “under the hood” to switch from the real-changesets data to the new adiffs.osmcha.org data.
-
OSMCha no longer depends on the changeset-map package, which used to provide all of OSMCha’s map rendering capabilities. The way changeset-map works turned out to be closely coupled with the real-changesets JSON format, and the way it was integrated into the OSMCha codebase was also complex and tricky to modify. So instead I reimplemented the map rendering behavior (and only the map rendering behavior) in a new package called maplibre-adiff-viewer. This package is easy to embed into other projects, so you can use it anywhere you’d like to render augmented diffs in the style of OSMCha. As an example, I used it to create the osmcha-cli command line tool, which you can launch from your terminal to view any augmented diff file in your web browser (no website required).
-
As its name suggests, maplibre-adiff-viewer is a plugin for MapLibre GL JS, an open-source map rendering engine. The changeset-map package depends on an old version of the Mapbox SDK; newer versions of Mapbox SDK are not open source, so migrating to MapLibre made sense for OSMCha.
-
To comply with Mapbox’s Terms of Service, and to improve user privacy, OSMCha no longer loads map tiles, stylesheets, fonts, icons, or other resources from mapbox.com. Instead, these assets are loaded from OSM US servers, or directly from satellite imagery providers (for satellite basemaps) or openstreetmap.org (for the OSM Carto basemap).
Overall, these changes took about 200 hours to develop. OSMCha is an OpenStreetMap US Charter Project, which means that OSM US provides funding to develop and maintain OSMCha. If you benefit from OSMCha, consider donating to support its development (OSM US is a 501(c)(3) nonprofit organization).
What’s next
There are more improvements coming soon to OSMCha, including:
-
Upgrading the backend to Django 5.2 (it currently uses Django 2.2)
-
Making the changeset list load faster by tuning the SQL queries used to retrieve this data (in particular, by switching to cursor-based pagination instead of offset-based pagination)
-
Optimizing polygon-based filtering of changesets, so that it’s faster to view recent changes in your area of interest
-
Improving accessibility of the web interface for people who navigate using a keyboard, rely on a screen reader, or who have color vision deficiency
If you are interested in helping to shape the future of OSMCha, here are some ways you can get involved:
-
Join the #osmcha channel on the OSM US Slack to ask questions or share feedback
-
Make a feature request or report a bug on our GitHub repository
-
Support OSM US financially by becoming an Individual Member. Membership fees directly support our operations, including software development and maintenance
-
If your company relies on OSMCha, consider funding development by becoming an Organizational Member
Finally, I’d like to say thank you to everyone who uses OSMCha. By volunteering your time and knowledge to review edits to OpenStreetMap, you are helping to make OSM the most accurate source of geographic information available anywhere. I hope that these changes to OSMCha make it faster and easier for you to review edits in your queue. Please continue to provide feedback so that we can make OSMCha serve you better.